




What we are going to upgrade
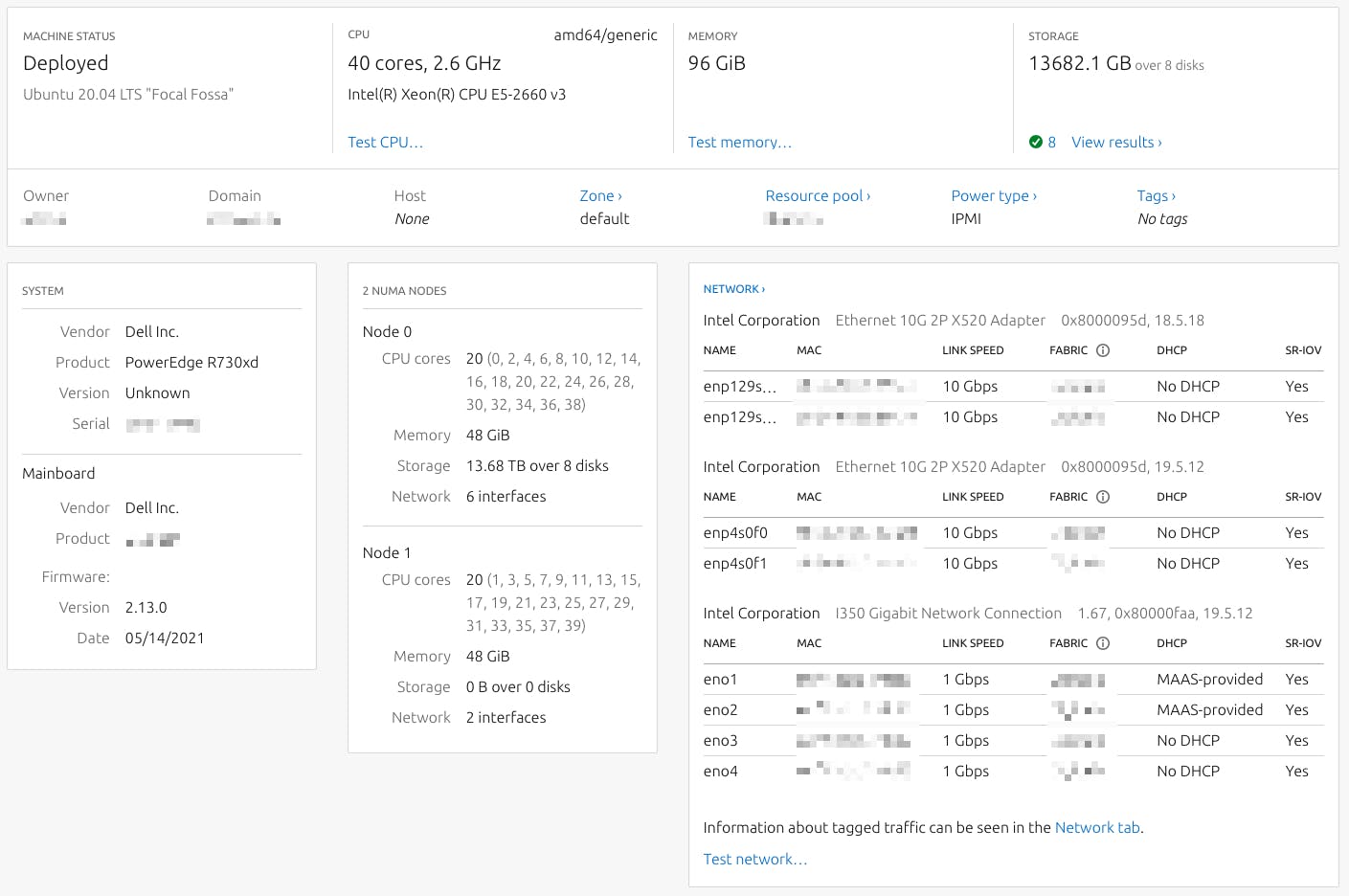
We have a small cluster of three nodes. I know it's a small cluster, but we are just starting with Ceph. All three bare-metal nodes were deployed with MAAS and have these resources:
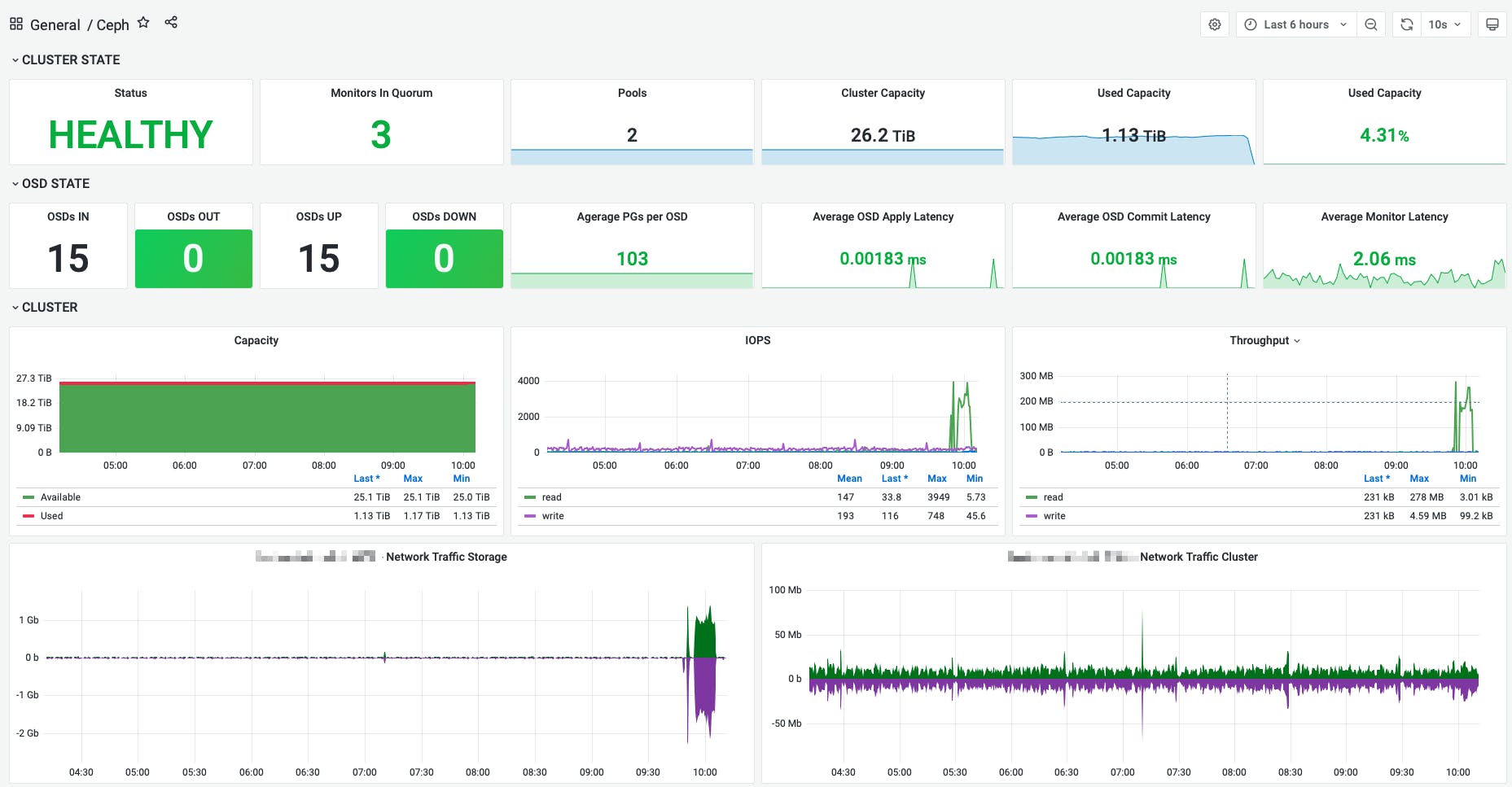
We are using 5 SSDs for OSD and two are as spare for now with one RBD Pool for vSphere with replica 3. Because vSphere doesn't support RBD natively, we choose as a connector iSCSi.
iSCSI Gateways are spread across the nodes. There are two RBD images, one for a public Cloud and another for internal use with two iSCSi targets. In total, we have 6 ESXi nodes connected.
We are in the pilot stage, where we are learning how Ceph works, so we are running only few VMs within cluster.
Here is how it looks like in the Grafana dashboard:
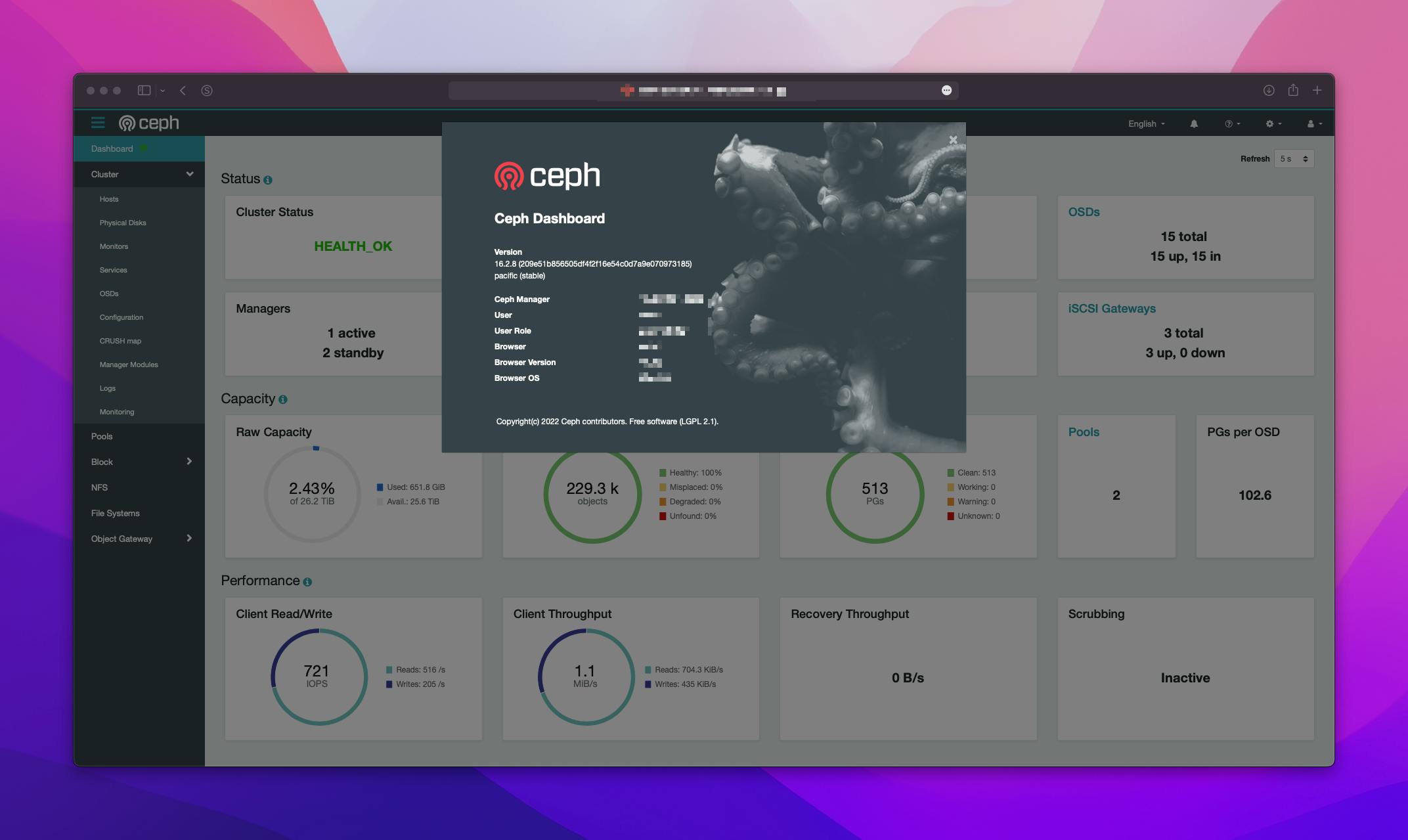
Upgrade
All commands are run as a cephadmin user with root passwordless access with cephadm shell.
Run command to check if a new version is available. This command also pulls a new image if it is available, so it's not needed to pull it within the upgrade process.
sudo cephadm shell -- ceph orch upgrade check --ceph-version 16.2.8
If you want to pull image on another nodes as I do run command to pull image on another nodes.
It's 1,23Gb, so I believe it's better to pull it before the upgrade process.
sudo docker image pull quay.io/ceph/ceph:v16.2.8
Run command to upgrade.
sudo cephadm shell -- ceph orch upgrade start --ceph-version 16.2.8
You can also watch the cephadm log by running the following command:
sudo cephadm shell -- ceph -W cephadm
The upgrade in our environment was successfully completed. There were only a few strange logs during the upgrade, like:
2022-05-17T09:08:43.855151+0000 mgr.ceph-01.ufldue [WRN] Failed to set Dashboard config
for iSCSI: dashboard iscsi-gateway-add failed: Traceback (most recent call last):
File "/usr/share/ceph/mgr/mgr_module.py", line 1448, in _handle_command
return CLICommand.COMMANDS[cmd['prefix']].call(self, cmd, inbuf)
File "/usr/share/ceph/mgr/mgr_module.py", line 414, in call
return self.func(mgr, **kwargs)
File "/usr/share/ceph/mgr/mgr_module.py", line 450, in check
return func(*args, **kwargs)
File "/usr/share/ceph/mgr/dashboard/services/iscsi_cli.py", line 36, in
add_iscsi_gateway
IscsiGatewaysConfig.add_gateway(name, service_url)
File "/usr/share/ceph/mgr/dashboard/services/iscsi_config.py", line 87, in
add_gateway
config = cls.get_gateways_config()
File "/usr/share/ceph/mgr/dashboard/services/iscsi_config.py", line 105, in
get_gateways_config
return cls._load_config_from_store()
File "/usr/share/ceph/mgr/dashboard/services/iscsi_config.py", line 48, in
_load_config_from_store
cls.update_iscsi_config(config)
File "/usr/share/ceph/mgr/dashboard/services/iscsi_config.py", line 58, in
update_iscsi_config
for gateway_name, gateway_config in config['gateways'].items():
RuntimeError: dictionary changed size during iteration
retval: -22
Edit: Here is the bug report of the mentioned issue raised after our report of the issue.
but it seems all fine.We can see iSCSI targets on the dashboard and everything works as expected. We also run shell script on VM stored on ceph datastore to see gaps during the upgrade.
 Here is the script:
Here is the script:
#!/bin/bash
while [ true ];do
date > $1/readwrite.txt
cat $1/readwrite.txt
echo --
sleep 1
done
This script will return every second current timestamp like:
Tue May 17 09:01:55 UTC 2022
--
Tue May 17 09:01:56 UTC 2022
--
Tue May 17 09:01:57 UTC 2022
--
During our update there was only few gaps in timestamp like
Tue May 17 09:02:53 UTC 2022
--
Tue May 17 09:02:54 UTC 2022
--
Tue May 17 09:02:58 UTC 2022
--
Tue May 17 09:02:59 UTC 2022
--
and datastore was all the time connected with iSCSi gateways without problem.
Conclusion
The whole upgrade of the Ceph with cephadm is really fully automated. There are a few health alerts that can arise during the upgrade process, but you can ignore them. The upgrade of the mentioned cluster took less than 10 minutes.